

AI Agents: Research & Applications

In recent years, the concept of an agent has become increasingly significant across various fields, including philosophy, gaming, and AI. In its traditional sense, agency refers to an entity's ability to act autonomously, make choices, and exercise intentionality—qualities historically associated with humans.
More recently in AI, agency has evolved into something more complex. With the advent of autonomous agents, which can observe, learn, and act independently in their environments, the once abstract concept of agency is now embodied in computational systems. These agents operate with minimal human oversight and display levels of intentionality that, while computational rather than conscious, enable them to make decisions, learn from experiences, and interact with other agents or humans in increasingly sophisticated ways.
This piece explores the emerging landscape of autonomous agents, specifically Large Language Model (LLM)-based agents, and their impact across diverse domains such as gaming, governance, science, robotics, and more. Building on foundational agentic principles, this piece examines both the architecture and application of AI agents. Through this taxonomy, we gain insights into how these agents perform tasks, process information, and evolve within their specific operational frameworks.
The objective of this piece is twofold:
To provide a structured overview of AI agents and their architectural foundations, focusing on components such as memory, perception, reasoning, and planning.
To examine the latest trends in AI agent research, highlighting applications where agents are redefining what is possible.
Side Note: Due to the length of this piece, I wanted to highlight that the sidebar has a table of contents for ease of navigation.
Trends in Agent Research
The development of LLM-based agents represents a significant milestone in AI research, reflecting progress through successive paradigms in symbolic reasoning, reactive systems, reinforcement learning, and adaptive learning techniques. Each of these stages contributed distinct principles and methodologies that have shaped today's LLM-based approaches.
Symbolic Agents
Symbolic agents, rooted in early AI research, relied on symbolic AI, using logical rules and structured knowledge representations to mimic human reasoning. These systems approached reasoning in a structured, interpretable manner, similar to human logic. A prominent example is knowledge-based expert systems, designed to solve specific problems by encoding domain expertise into rule-based frameworks (e.g., medical diagnosis or chess engines).
Symbolic agents offer high interpretability and expressiveness in decision-making, allowing clear explanations of actions. However, they face limitations with uncertainty and scalability when applied to complex, dynamic environments. Their computational demands often hinder efficiency, particularly in real-world scenarios requiring adaptability and speed.
Reactive Agents
Reactive agents marked a shift from complex symbolic reasoning towards faster, simpler models designed for real-time interaction. Operating through a sense-act loop, these agents perceive their environment and immediately respond, avoiding deep reasoning or planning. The focus here is on efficiency and responsiveness rather than cognitive complexity.
Reactive agents are computationally lightweight, making them ideal for environments where rapid responses are crucial. However, their simplicity limits them from handling higher-level tasks such as planning, goal-setting, or adapting to complex, multi-step problems. This restricts their usefulness in applications that require sustained, goal-oriented behavior.
Reinforcement Learning-Based Agents
Advancements in computational power and data availability brought reinforcement learning (RL) to the forefront, enabling agents to exhibit adaptive behavior in complex environments. RL agents learn through trial and error, interacting with their surroundings and adjusting actions based on rewards. Techniques like Q-learning and SARSA introduced policy optimization, with deep reinforcement learning integrating neural networks to process high-dimensional data (e.g., images, games). AlphaGo exemplifies this approach, using these methods to defeat human champions in Go.
RL agents can autonomously improve performance in dynamic environments without human oversight, making them valuable for applications in gaming, robotics, and autonomous systems. However, RL faces challenges such as lengthy training periods, sample inefficiency, and stability issues, particularly in more complex scenarios.
LLM-Based Agents
The emergence of LLMs has redefined AI agent design, positioning LLMs as the “brains” of these agents, capable of understanding and generating natural language with high accuracy and flexibility. LLMs combine elements of symbolic reasoning, reactive feedback, and adaptive learning, utilizing methods like Chain-of-Thought (CoT) prompting and problem decomposition. This enables structured reasoning while maintaining responsiveness.
LLM-based agents also demonstrate few-shot and zero-shot learning capabilities, allowing them to generalize across new tasks with minimal examples. Their versatility spans applications from software development to scientific research and automation. Their ability to interact naturally and adaptively with other agents leads to emergent social behaviors, including cooperation and competition, making them suitable for collaborative environments.
Moreover, LLM-based agents are capable of multi-domain task-switching without requiring parameter updates, enhancing their usefulness in complex, dynamic environments. By combining interpretability, adaptive learning, and natural language processing, they offer a balanced, highly capable framework for modern AI applications.
The rest of this piece will focus on the architecture, capabilities, and limitations of LLM-based agents.
Agentic Architecture
The modern agentic architecture can be understood as an amalgamation of various modules that comprise the agent. In the following, we’ll consider a general taxonomy of agentic architecture based primarily on the frameworks provided in A Survey on Large Language Model based Autonomous Agents and The Rise and Potential of Large Language Model Based Agents: A Survey.
Profile
In autonomous agent design, the profile module is vital to guiding agent behavior by assigning specific roles (such as teachers, coders, or domain experts) or personalities. These profiles influence both the consistency and adaptability of the agent’s responses. The profile module essentially serves as a behavioral scaffold, setting parameters that help agents align with their designated role or personality during subsequent interactions. This guidance is essential for role-based performance and coherence in response generation, as well as in applications requiring sustained personality traits.
As explored in From Persona to Personalization: A Survey on Role-Playing Language Agents, personas in LLM-based agents can be classified into three main types:
Demographic Persona: This persona represents characteristics of a demographic, such as occupation, age, or personality type. Demographic personas are often used in social simulations or applications aimed at enhancing output relevance and contextual accuracy. For example, an agent might adopt the characteristics of a data scientist to provide targeted technical insights.
Character Persona: Here, the agent embodies a fictional character or public figure, often for purposes of entertainment, gaming (e.g., non-player characters), or companionship. This type is widely used in conversational AI and virtual companions, where the agent’s persona adds immersion and engagement to the user experience.
Individualized Persona: The agent is customized to reflect the behavior, preferences, and unique traits of a specific individual, akin to a personalized assistant. This persona type is typically used in applications where an agent functions as a proxy for an individual or where the agent acts as an assistant that adapts to a specific user’s preferences and behaviors over time.

These personas have been shown to enhance both performance and reasoning capabilities across a variety of tasks. For example, a persona-based approach allows an LLM to provide more in-depth and contextually relevant responses when embodying an expert demographic. Furthermore, in multi-agent systems, such as ChatDev and MetaGPT, persona use facilitates cooperative problem-solving by aligning agent behaviors with task-specific roles, contributing positively to task completion and interaction quality.
Methods of Profile Creation
Various methods are employed to construct and refine profiles in LLM-based agents, each with strengths and considerations:
Handcrafting: Profiles are manually defined, with human input specifying the details. For example, a user may configure an agent to be “introverted” or “outgoing” to reflect specific personality traits.
LLM-Generation: In this approach, profiles are generated automatically using LLMs, starting from a few seed examples. This method allows for efficient scaling and adaptation. For instance, RecAgent generates initial profiles with attributes like age, gender, and personal interests, using ChatGPT to expand these profiles across a large user base.
Dataset Alignment: Profiles derived from real-world datasets, such as demographic studies, enable agents to mirror realistic social behaviors. This method enhances the authenticity of interactions by anchoring agent behavior in empirical data.
Memory
Memory is a foundational component in LLM-based agents, storing information gathered from the environment to enable adaptive planning and decision-making. Much like human memory, agent memory plays a crucial role in handling sequential tasks and formulating strategies.
Memory Structure
The structure of memory in LLM-based agents is inspired by cognitive science, particularly the human memory model, which progresses from sensory input to short-term and long-term retention. In AI agents, memory is typically structured into two main types:
Unified Memory
Unified memory simulates a short-term memory system, focusing on recent observations that can be directly incorporated into prompts for immediate response. This approach is straightforward to implement and excels in enhancing the agent’s awareness of recent, contextually sensitive information. However, unified memory is fundamentally limited by the context window size inherent in transformer models.
To manage context window limitations, several techniques have been developed:
Text Truncation and Segmented Inputs: These methods selectively condense or divide incoming information to fit within context limits.
Memory Summarization: Key data from interactions are distilled into concise summaries before reintroduction to the agent, maintaining relevance without overwhelming the context window.
Attention Mechanism Modification: Custom attention mechanisms can help the model prioritize relevant recent information.
Despite its simplicity, unified memory is constrained by the finite context windows of current LLMs, which can limit scalability and efficiency when handling extensive information.
Hybrid Memory
Hybrid memory combines both short-term and long-term memory structures. Here, short-term memory serves as a transient buffer, capturing the agent’s immediate environment, while long-term memory preserves reflections or useful insights in an external database for later retrieval.
A common implementation for long-term memory storage is the use of vector databases, where thoughts are encoded as embeddings. This approach enables retrieval through similarity search, allowing agents to recall past interactions effectively.
Memory Formats
Memory can be stored in various formats, each suited for different applications. Some common formats include:
Natural Language: Memory is stored as raw text, offering flexibility and rich semantic content. Agents like Reflexion and Voyager use natural language to store feedback and skills, respectively.
Embeddings: Memory is encoded into vectors, making retrieval and search of contextually similar memories more efficient. Tools like MemoryBank and ChatDev store memory segments as embeddings for quick access.
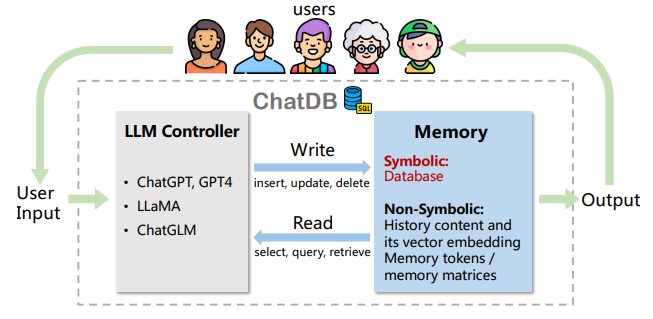
Databases: Structured databases allow agents to manipulate memories using SQL-like queries. Examples include ChatDB and DB-GPT.
Structured Lists: Memory can also be stored in lists or hierarchies. For example, GITM organizes sub-goals into action lists, while RET-LLM converts sentences into triplets for efficient memory storage.
Memory Operations
Memory operations are essential for agents to interact with their stored knowledge. These include:
Memory Reading: This operation involves retrieving relevant information from memory, guided by recency, relevance, and importance. The ability to extract meaningful data improves the agent's ability to make informed decisions based on past actions.
Memory Writing: Storing new information in memory is a nuanced process that must manage duplicates and prevent memory overflow. For example, Augmented LLM consolidates redundant data to streamline memory, while RET-LLM employs a fixed-size buffer that overwrites older entries to avoid saturation.
Memory Reflection: Reflection enables agents to summarize past experiences and derive high-level insights. In Generative Agents, for instance, the agent reflects on recent experiences to form broader conclusions, enhancing its capacity for abstract reasoning.

Research Implications and Challenges
While memory systems significantly improve agent capabilities, they also present several research challenges and open questions:
Scalability and Efficiency: Scaling memory systems to support large volumes of information while maintaining quick retrieval is a key challenge. Hybrid memory systems offer a promising solution, but optimizing long-term memory retrieval without compromising performance remains a research focus.
Handling Context Limitations: Current LLMs are bound by finite context windows, which limits their ability to manage extensive memories. Research into dynamic attention mechanisms and summarization techniques continues to explore ways to extend effective memory handling.
Bias and Drift in Long-Term Memory: Memory systems are vulnerable to bias, where certain types of information are favored over others, potentially leading to memory drift. Regularly updating memory content and implementing bias correction mechanisms are crucial for ensuring balanced, reliable agent behavior.
Catastrophic Forgetting: One of the most significant challenges in memory-based agent systems is catastrophic forgetting, where agents lose critical information from long-term memory due to new data overwriting older, but still valuable, knowledge. This problem is especially pronounced when memory storage is constrained, forcing agents to selectively retain information. Solutions under exploration include experience replay, where past information is revisited periodically, and memory consolidation techniques, inspired by human neural processes, to solidify key learnings.
Perception
Just as humans and animals rely on sensory inputs like vision, hearing, and touch to interact with their surroundings, LLM-based agents benefit from processing diverse data sources to enhance their understanding and decision-making capabilities. Multimodal perception, which integrates various sensory modalities, enriches an agent’s awareness, allowing it to perform more complex and context-sensitive tasks.
This section outlines key types of inputs—textual, visual, auditory, and emerging sensory modalities—that equip agents to operate across a range of environments and applications.
Textual Input
Text serves as the foundational modality for knowledge exchange and communication in LLM-based agents. While agents have advanced language capabilities, interpreting the implied or contextual meaning behind instructions remains an area of research. Understanding the subtleties of user instructions, such as beliefs, desires, and intentions, requires the agent to go beyond literal interpretations to discern underlying meanings.
Implicit Understanding: To interpret implied meaning, reinforcement learning techniques are often employed, enabling agents to align responses with user preferences based on feedback. This approach allows agents to better handle ambiguity, indirect requests, and inferred intent.
Zero-Shot and Few-Shot Capabilities: In real-world scenarios, agents frequently encounter unfamiliar tasks. Instruction-tuned LLMs demonstrate zero-shot and few-shot understanding, which allows them to respond accurately to new tasks without additional training. These capabilities are especially useful for adapting to user-specific contexts and varying interaction styles.
Visual Input
Visual perception enables agents to interpret objects, spatial relationships, and scenes, providing contextual information about their surroundings.
Image-to-Text Conversion: A simple approach for handling visual data is to generate captions or descriptions that the agent can process as text. While helpful, this method has limitations, such as reduced fidelity and potential loss of nuanced visual information.
Transformer-Based Encoding: Inspired by NLP transformer models, researchers have adapted similar architectures, like Vision Transformers (ViT), to encode images into tokens compatible with LLMs. This approach allows agents to process visual data in a more structured manner, with improved capacity to analyze detailed image features.
Bridging Tools: Tools like BLIP-2 and InstructBLIP use intermediate layers (e.g., Q-Former) to bridge visual and textual modalities. These models reduce computational demands and mitigate catastrophic forgetting by aligning visual data with textual inputs. For video input, tools like Flamingo maintain temporal coherence by using masking mechanisms, enabling agents to interpret sequences accurately over time.
Auditory Input
Auditory perception enhances an agent’s awareness by allowing it to process sounds, detect speech, and respond to auditory cues. This capability is vital for agents involved in interactive or high-stakes environments, where sound provides critical real-time context.
Speech Recognition and Synthesis: With the integration of tool-using capabilities, LLM-based agents can leverage specialized audio models. For instance, AudioGPT combines tools like Whisper for speech recognition and FastSpeech for text-to-speech, enabling agents to handle speech-to-text and vice versa effectively.
Spectrogram Processing: Some approaches treat audio spectrograms as 2D images, allowing the use of visual encoding techniques like Audio Spectrogram Transformers. This method leverages existing visual processing architectures, allowing the agent to interpret auditory signals more efficiently.
Emerging Input Modalities
Beyond text, vision, and audio, additional sensory inputs are beginning to expand the interaction capabilities of LLM-based agents, enabling richer, environment-aware actions.
Tactile and Environmental Sensors: Agents could potentially incorporate sensors for touch, temperature, humidity, and brightness.
Gesture and Eye-Tracking: Technologies like InternGPT enable users to interact with images using gestures, while eye-tracking and body motion capture expand agents’ ability to interpret complex human behaviors. These modalities are particularly promising in augmented and virtual reality applications, where precise user input enhances engagement and control.
Spatial Awareness: Tools like Lidar generate 3D point clouds, which help agents detect objects and understand spatial dimensions. Combined with GPS and Inertial Measurement Units (IMUs), agents gain real-time object tracking capabilities, allowing for dynamic interaction with moving entities. Advanced alignment mechanisms are essential for integrating this data into LLMs effectively.
Research Challenges and Considerations in Multimodal Perception
While multimodal perception enhances agent functionality, it introduces several research challenges and technical considerations:
Data Alignment and Integration: Integrating diverse sensory data requires alignment mechanisms that can combine textual, visual, and auditory inputs cohesively. Misalignment between modalities can lead to errors in perception and response. Techniques like multimodal transformers and cross-attention layers are under investigation to improve seamless data integration.
Scalability and Efficiency: Multimodal processing significantly increases computational demands, especially when handling high-resolution images, video frames, and continuous audio. Developing scalable models that can handle multimodal data without excessive resource use is a pressing area of research.
Catastrophic Forgetting: Just as with memory systems, catastrophic forgetting is a risk in multimodal agents that must manage multiple input types across varying contexts. Retrieving essential information while accommodating new data requires innovative strategies, such as prioritized replay and continuous learning frameworks, to retain vital sensory knowledge without overwhelming the model.
Context-Sensitive Response Generation: Generating responses that appropriately reflect multimodal input is complex, as agents must prioritize relevant sensory data based on context. For example, in a crowded auditory environment, sound cues may take precedence, while in a visual-heavy scene, spatial data might be more crucial. Context-driven response generation remains an active research area to enhance agent adaptability.
Reasoning & Planning
The reasoning and planning module empowers AI agents to tackle complex tasks by breaking them into smaller, manageable steps, much like how humans approach intricate problems. This module enhances the agent’s ability to create structured plans, either by forming a comprehensive plan upfront or by adapting in real time based on new feedback.
In AI, planning approaches are typically classified by the degree and type of feedback used. Some agents construct entire plans upfront, following a single path or exploring multiple options without altering the plan during execution. Other agents operate in dynamic environments, adapting their strategies as they receive feedback from the environment, humans, or other models, enabling continuous improvement and adaptation.
Side Note: A useful guide of prompting techniques is available in the paper The Prompt Report: A Systematic Survey of Prompting Techniques.
Planning without Feedback
In planning without feedback, agents create a full plan at the start and follow it without any changes. This approach includes both single-path and multi-path methods. Single-path planning is straightforward, with each step leading directly to the next. Multi-path planning explores different options at once, letting the agent choose the best path. These strategies help agents complete tasks consistently and effectively, even without adjustments along the way.
Single-Path Reasoning
Single-path reasoning breaks tasks into straightforward, sequential steps. Each step leads directly to the next, like following a single chain.
Examples:
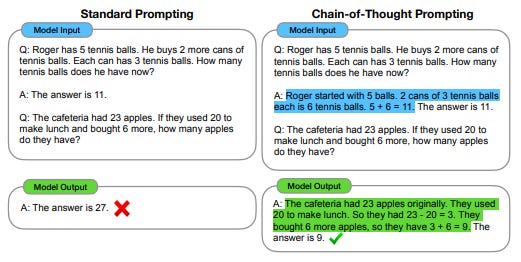
Chain of Thought (CoT): Encourages step-by-step problem solving by prompting the LLM with few-shot examples of reasoning steps. This technique has been shown to significantly improve the model's output quality, even compared to fine-tuned, application-specific models.
Zero-Shot-CoT: Initiates stepwise reasoning without predefined examples using prompts like “think step by step.” This method performs comparably to CoT and is more generalizable, making it effective for zero-shot learning.
RePrompting: An algorithm that automatically discovers effective CoT prompts using question-answer pairs without human input.
Multi-Path Reasoning
In contrast to single-path reasoning, multi-path reasoning allows agents to explore various steps simultaneously, generating multiple potential solutions and evaluating them to select the best path. This method is useful for complex problem-solving, where multiple possible approaches exist.
Examples:
Self-consistent CoT (CoT-SC): Generates multiple reasoning paths by sampling from the outputs of a CoT prompt and selecting the steps occurring with the highest frequency. One could think of this as a “self-ensemble” that works on top of a single model.
Tree of Thoughts (ToT): Stores each logical step in a tree structure, enabling the LM to evaluate how each “thought” contributes toward a solution. ToT can be navigated systematically using search heuristics like breadth-first search (BFS) or depth-first search (DFS).
Graph of Thoughts (GoT): Expands the ToT concept into a graph structure, with thoughts as vertices and dependencies as edges, allowing more flexible and interconnected reasoning.
Reasoning via Planning (RAP): Uses Monte Carlo Tree Search (MCTS) to simulate multiple plans, with the LLM acting as both an agent (building the reasoning tree) and a world model (providing feedback and rewards).
External Planners
When LLMs face domain-specific planning challenges, external planners offer specialized support, integrating task-specific knowledge that LLMs may lack.
Examples:
LLM+P: Converts tasks into Planning Domain Definition Languages (PDDL) and solves them with an external planner. This method has been shown to enable LLMs to complete complex tasks, such as robotic manipulation, by translating natural language instructions into actionable plans.
CO-LLM: The approach involves models collaborating by generating text one token at a time, with each token alternated between models. The choice of which model generates each token is treated as a latent variable, without explicit guidance on model selection per step. This allows an optimal collaboration pattern to emerge naturally from the data for each task, delegating planning responsibilities to domain-specific models as needed.
Planning with Feedback
Planning with feedback equips agents to adapt to changes in their environment. As they move through tasks, they can adjust their plans based on new information from their surroundings, interactions with humans, or feedback from other models. This dynamic approach is essential for handling unpredictable or complex scenarios, where initial plans may need fine-tuning along the way.
Environmental Feedback
In situations where agents interact with their surroundings or virtual environments, they can adjust plans based on real-time feedback from their perception of the world. If they encounter obstacles or unforeseen challenges, the planner module revises its approach. This responsiveness helps the agent stay on track.
Examples:
ReAct: Combines reasoning traces and action-based prompts, allowing the agent to create high-level, adaptable plans while interacting with its environment.
Describe, Explain, Plan, and Select (DEPS): Used in task planning (e.g., Minecraft controllers), DEPS revises plans upon encountering errors. When a sub-goal is unfulfilled, the descriptor module summarizes the situation, the explainer identifies errors, and the planner revises and reattempts the task.
SayPlan: Uses scene graphs and state transitions from simulated environments to refine its strategies, ensuring a more context-aware approach to task completion.

Human Feedback
Human interaction helps agents align with human values and avoid errors.
Examples:
Inner Monologue: Collects scene descriptions and integrates human feedback into the agent’s planning process, aligning agent actions with human expectations.
Model Feedback
Internal feedback from pre-trained models allows agents to self-check and refine their reasoning chains and actions.
Examples:
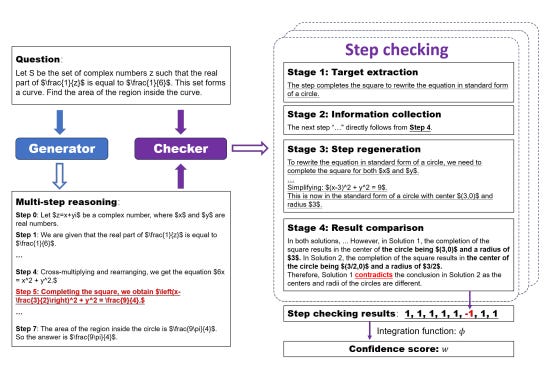
SelfCheck: A zero-shot step-by-step checker for self-identifying errors in produced reasoning chains. SelfCheck uses an LLM to check conditional correctness based on preceding steps with the results used to form a correctness estimation.
Reflexion: Agents reflect on task performance by logging feedback signals into an episodic memory buffer, enhancing long-term learning and error correction through internal reflection.
Challenges and Research Directions in Reasoning & Planning
While the reasoning and planning module greatly improves agent functionality, several challenges remain:
Scalability and Computational Demands: Multi-path reasoning, particularly with complex methods like ToT or RAP, requires substantial computational resources. Ensuring that these planning techniques can scale efficiently remains an active research challenge.
Feedback Incorporation Complexity: Incorporating feedback effectively, especially from dynamic or multi-source environments, is complex. Designing methods that prioritize relevant feedback while avoiding overwhelm is essential for improving agent adaptability without sacrificing performance.
Bias in Decision-Making: Bias can arise if agents prioritize certain feedback sources or paths over others, potentially leading to skewed or suboptimal decision-making. Incorporating bias mitigation techniques and diverse feedback sources is critical for balanced planning.
Action
The action module is the final stage in an AI agent's decision-making process, executing actions based on planning and memory to interact with the environment and produce outcomes. This module includes four key subcategories: action goal, action production, action space, and action impact.
Action Goal
AI agents can act toward a variety of objectives. Some representative examples include:
Task Completion: Actions achieve specific goals, like crafting tools in Minecraft or completing functions in software development.
Communication: Agents interact with humans or other agents to share information. For example, ChatDev agents communicate to complete programming tasks.
Environment Exploration: Agents explore new environments to gain insights, as in Voyager, where the agent experiments with and refines new skills.
Action Production
Agents generate actions by recalling memories or following plans:
Memory-Based Actions: Agents leverage stored information to guide decisions. For example, Generative Agents retrieve relevant memories before each action.
Plan-Based Actions: Agents execute predefined plans unless interrupted by failure signals. For instance, DEPS agents follow plans until completion.
Action Space
The action space consists of two main categories: internal knowledge and external tools.
Many agents rely on the inherent abilities of LLMs which have been found to be very successful in generating actions based on the pre-trained knowledge of the LLM. However, there are a variety of areas in which an agent might need to rely on external tools to implement an action. Agents can also look to use APIs, databases, or external models in these situations:
APIs: Tools like HuggingGPT use HuggingFace models to perform complex tasks. ToolFormer transforms tools into new formats using LLMs, and RestGPT connects agents with RESTful APIs for real-world applications.

Databases & Knowledge Bases: ChatDB employs SQL queries to retrieve domain-specific information, while MRKL integrates expert systems and planners for complex reasoning.
External Models: Agents may rely on models beyond APIs for specialized tasks. For instance, ChemCrow uses multiple models to perform drug discovery and material design, and MemoryBank employs two models to enhance text retrieval.
Action Impact
The impact of actions is categorized by outcome:
Environment Alteration: Actions can directly alter the environment. In Voyager and GITM, agents modify their surroundings by gathering resources or building structures (e.g., mining wood results in it disappearing from the environment and appearing in inventory).
Self-Impact: Actions can update memory, form new plans, or add knowledge, as seen in Generative Agents’ memory streams.
Task Chaining: Some actions trigger others, such as Voyager building structures only after resource collection.
Extending the Action Space
Designing effective AI agents requires not only robust architecture but also task-specific skills and experiences. These "capabilities" can be seen as the software that powers the agent's ability to perform well in various scenarios. This section explores the two main strategies for capability acquisition: with fine-tuning and without fine-tuning.
Capability Acquisition with Fine-tuning
Fine-tuning enhances the agent's performance by adjusting the model’s parameters using specialized datasets. The datasets can come from human annotation, LLM-generated data, or real-world collections.
Fine-tuning with Human-annotated Datasets
This involves recruiting human workers to annotate datasets for specific tasks.
Examples:
RET-LLM: Fine-tunes LLMs to convert natural language into structured memory by using human-created “triplet-natural language” pairs.
EduChat: Enhances LLMs for educational purposes using expert-annotated data covering teaching, essay assessment, and emotional support scenarios.
Fine-tuning with LLM-Generated Datasets
LLMs generate datasets, reducing costs compared to human annotation. While not perfect, these datasets are cheaper to produce and can cover more samples. Most notable here is ToolBench, which uses ChatGPT to generate diverse instructions for real-world API usage, leading to the fine-tuning of LLaMA for better tool execution.
Fine-tuning with Real-world Datasets
Agents are trained using datasets collected from real-world applications. For example, MIND2WEB fine-tunes LLMs with over 2,000 open-ended tasks collected from 137 websites, improving their performance on tasks like booking tickets and finding movies. As another example, SQL-PaLM uses a large text-to-SQL dataset (Spider) to fine-tune LLMs for database query tasks.
Capability Acquisition Without Fine-tuning
In scenarios where fine-tuning is impractical, agents can acquire capabilities through prompt engineering and mechanism engineering.
Prompt Engineering
Prompt engineering enhances agent performance by carefully designing prompts that guide the LLM’s behavior.
Examples:
Chain of Thought (CoT): Introduces intermediate reasoning steps in prompts to enable complex problem-solving.
SocialAGI: Uses self-awareness prompts to help agents align their conversations with the mental states of users and listeners.
Retroformer: Integrates reflections on past failures into prompts, improving future decisions through iterative verbal feedback.
Mechanism Engineering
Mechanism engineering uses specialized rules and mechanisms to enhance the agent’s capabilities beyond prompt manipulation. Below are some key strategies:
Trial-and-Error:
Describe, Explain, Plan and Select (DEPS): Enhances error correction in LLM-generated plans by incorporating execution process descriptions, self-explained feedback for failure handling, and a trainable goal selector module that ranks candidate sub-goals based on estimated completion steps, optimizing and refining the planning process.
RoCo: Agents adjust their multi-robot collaboration plans based on environmental checks, such as collision detection.
Crowdsourcing:
Debate Mechanism: Agents collaborate and revise their solutions iteratively until reaching consensus through crowd wisdom.
Experience Accumulation:
GITM: Uses a text-based memory mechanism to explicitly store and retrieve knowledge in a logical, human-aligned format, enabling efficient learning and improved generalization by summarizing essential actions from multiple executed plans to create adaptable reference plans.
Voyager: Refines skill execution codes based on self-verification and feedback during interaction with the environment.
Self-driven Evolution:
LMA3: By supporting a relabeler for achieved goals, a goal generator for decomposing high-level goals into mastered subgoals, and reward functions for goal evaluation, LMA3 enables agents to acquire a wide range of skills in a task-agnostic text-based environment without relying on hand-coded goal representations or predefined curricula.
Fine-tuning offers powerful task-specific performance improvements but requires open-source models and is resource-intensive. Prompt engineering and mechanism engineering work with both open- and closed-source models but are limited by the input context window and require careful design.
Multi-Agent Architecture

Multi-agent architectures distribute tasks across several agents, each specializing in different aspects of the problem. This design allows for multiple agents independently working toward its assigned goal using specialized tools.
Multi-agent systems offer significant advantages in terms of robustness and adaptability. The collaboration between agents allows them to provide feedback to one another, which improves the overall execution and prevents individual agents from getting stuck. Additionally, these systems can adjust dynamically, assigning or removing agents based on the evolving needs of the task.
However, this architecture comes with coordination challenges. Effective communication between agents is critical to ensure important information is not lost or misinterpreted, as each agent only has partial knowledge of the overall goal.
Vertical & Horizontal Organization
To facilitate cross-communication and coordination among multiple agents, the research has primarily focused on two types of organizational structure: horizontal and vertical.
In a horizontal structure, all agents in a group share and refine their individual decisions, and the group’s collective decision is formed by combining these individual inputs using a function, like summarization or ensemble techniques. This democratic approach works well in scenarios like consulting or tool use, where diverse input is beneficial.
In contrast, a vertical structure involves a hierarchical process where one agent, the "solver," proposes an initial solution, and other agents provide feedback on it or alternatively where one agent acts as the manager overseeing the work of other agents. The solver refines the decision based on this feedback until consensus is reached or a set number of revisions is completed. This structure suits tasks needing a single, refined solution, such as math problem-solving or software development.
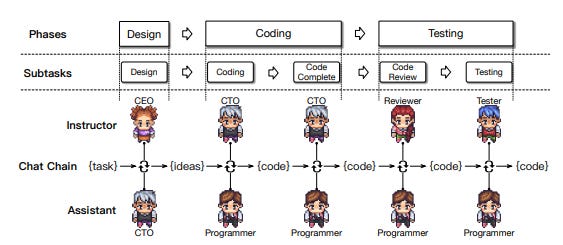
Hybrid Organization
Alternatively, it is possible to combine vertical and horizontal structures into a hybrid approach as is the case in the DyLAN paper.
DyLAN organizes agents into a multi-layered feed-forward network where agents interact on a peer level. This structure allows them to collaborate horizontally within each layer and exchange messages across time steps, resembling a horizontal collaboration architecture in that agents can operate independently and are task-agnostic.
However, DyLAN also introduces a ranker model and an Agent Importance Score system, creating a layer of hierarchy among agents. The ranker model dynamically evaluates and selects the most relevant agents (top-k agents) to continue collaboration, while low-performing agents are deactivated. This introduces a vertical hierarchy within the horizontal collaboration framework, as higher-ranking agents influence task completion and team composition.
Cooperative Multi-Agent Frameworks
In addition to hierarchical structure, multi-agent frameworks can be discussed as being either cooperative or adversarial.
In cooperative multi-agent systems, agents collaborate by sharing information and aligning their actions to maximize efficiency. Cooperative interaction focuses on the strengths of each agent, ensuring that they complement one another to achieve optimal outcomes.
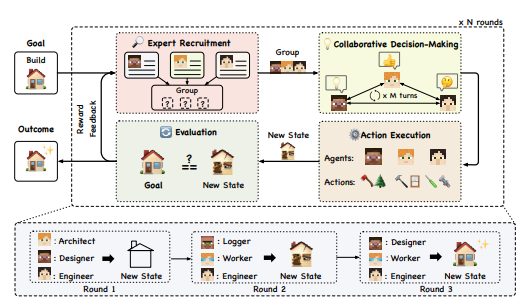
We can divide cooperative interactions into two key types:
Disordered Cooperation
In disordered cooperation, multiple agents interact freely without following a fixed sequence or workflow. This resembles brainstorming sessions, where every agent offers feedback, opinions, and suggestions openly. Systems like ChatLLM exemplify this approach by modeling agents as interconnected nodes within a neural network. Each agent processes inputs from others and passes the information forward, allowing for iterative refinement. However, disordered cooperation can become chaotic as large amounts of feedback may overwhelm the system.
To address these challenges, frameworks often introduce a coordinating agent responsible for integrating inputs and organizing responses. In some cases, majority voting mechanisms are employed to help the system reach a consensus. Despite its potential, disordered cooperation requires advanced strategies to manage information flow and extract meaningful insights effectively.
Ordered Cooperation
In ordered cooperation, agents interact in a sequential manner, following a structured flow. Each agent focuses only on the output from previous agents, creating a streamlined and efficient communication channel. This model is common in dual-agent systems, such as CAMEL, where one agent acts as a user giving instructions, and the other serves as an assistant providing solutions. By following a defined sequence of steps, ordered cooperation ensures rapid task completion and minimizes confusion.
This approach aligns closely with software development methodologies, where tasks progress through distinct phases. Frameworks like MetaGPT follow the waterfall model, with agents’ inputs and outputs standardized as engineering documents. This structure reduces ambiguity and ensures that tasks are completed systematically. However, even in ordered systems, the absence of proper constraints can lead to the amplification of small errors—such as hallucinations—resulting in flawed outcomes. Integrating techniques like cross-validation or timely human intervention helps prevent these pitfalls.

Adversarial Multi-Agent Frameworks
While cooperative methods offer efficiency and synergy, adversarial frameworks introduce a competitive edge, pushing agents to evolve by challenging each other. Drawing inspiration from game theory, adversarial interaction allows agents to engage in debates and competitive tasks. This approach promotes adaptability, encouraging agents to refine their behavior through constant feedback and critical reflection.
A prime example of adversarial systems is the RL-agent AlphaGo Zero, which achieved breakthroughs by playing against itself, refining strategies with each iteration. Similarly, adversarial multi-agent systems in the context of LLMs use debate to improve outputs. In this setting, agents express competing arguments, engaging in a “tit-for-tat” exchange that exposes flaws in reasoning. For example, ChatEval employs multiple agents to critique each other’s outputs, ensuring a level of evaluation comparable to that of human reviewers.
These debates force agents to abandon rigid assumptions and develop more nuanced responses through thoughtful reflection. However, the adversarial model introduces unique challenges, such as increased computational overhead and the risk of agents converging on incorrect conclusions. Without proper safeguards, competitive interactions can amplify minor errors across multiple agents, making it difficult to achieve reliable outcomes.
Emergent Behaviors in Multi-Agent Systems
Interestingly, the AgentVerse paper describes emergent behaviors observed in multi-agent organizations.
Volunteer behaviors in multi-agent systems reflect an agent’s willingness to contribute additional time, resources, or assistance beyond their assigned tasks. For example, agents may recognize inefficiencies in their initial task allocations—like when one agent finishes early and offers to help others instead of waiting idly. This "time contribution" can accelerate task completion by sharing efforts dynamically. Agents also often engage in “resource contributions,” where they share items or resources with peers to facilitate collective progress. Additionally, agents exhibit “assistance contributions” by aiding other agents struggling with specific tasks, allowing the group to progress cohesively toward shared goals.
Conformity behaviors emerge as agents adjust their actions to align with the group’s objectives. For example, if an agent deviates from its task, other agents may provide feedback or signals prompting it to refocus. This behavior reinforces cooperation by ensuring that all agents remain aligned with the team’s goals, similar to social norms in human groups. Conformity behaviors enhance the stability of task outcomes, as agents recalibrate their actions to synchronize with the group’s evolving objectives and maintain consistency within the system.
Destructive behaviors, while less frequent, illustrate cases where agents pursue shortcuts or aggressive actions to achieve task completion. These behaviors include actions like harming other agents to gain resources or damaging the environment—such as breaking a village library in Minecraft to gather books instead of crafting them. Destructive behaviors often arise from attempts to maximize efficiency under constraints, highlighting potential safety concerns if similar actions were replicated in real-world applications. Identifying and mitigating destructive behaviors is essential, as they can undermine group stability and pose risks, particularly in scenarios where agents work alongside humans.
Later on, we will also discuss the Generative Agents paper which showcased other emergent social behaviors during social simulation as well.
Benchmarking and Evaluation
Benchmarking is essential for evaluating the performance and effectiveness of autonomous agents and multi-agent systems. With advancements in LLMs and autonomous agents, benchmarks allow researchers to test these systems across multiple domains, using standardized metrics and protocols to measure key attributes such as reasoning, collaboration, safety, social awareness, and adaptability. Effective benchmarks offer critical insights into the strengths and weaknesses of agents, guiding their development and refinement. This section highlights some notable benchmarks and frameworks used to evaluate LLM-based agents.
Simulation Environments for Core Capabilities
Simulation environments are among the most popular benchmarks, offering controlled environments to test agent interactions, planning, and task performance. Platforms like:
ALFWorld, IGLU, and Minecraft allow agents to engage in simulated environments, helping researchers assess their problem-solving and interaction skills.
Tachikuma uses game logs from tabletop role-playing games (TRPGs) to evaluate agents' abilities to infer complex interactions between characters and objects, providing a real-world test of reasoning and creativity.
AgentBench introduces a comprehensive framework that tests LLM-based agents in real-world scenarios, becoming the first systematic benchmark for assessing LLMs’ performance across diverse environments.
Social Capability and Communication Evaluation
Some benchmarks assess the social competencies of agents, focusing on their ability to understand emotions, humor, credibility, and more nuanced human-like interactions:
SocKET evaluates LLMs across 58 social tasks, measuring agents’ understanding of emotions, humor, and social cues.
EmotionBench examines agents’ ability to respond emotionally to specific situations. It collects over 400 scenarios, comparing the emotional responses of agents and humans.
RocoBench tests agents on multi-agent collaboration in cooperative robotics, with a focus on communication and coordination strategies.
Tool Use and Problem-Specific Benchmarks
Other benchmarks focus on tool use and specialized problem-solving environments, helping evaluate an agent’s adaptability to real-world challenges:
ToolBench offers an open-source platform to support the development of LLMs with general tool-use capabilities, assessing how effectively they can learn and deploy tools.
GentBench evaluates how agents leverage tools to solve complex tasks, focusing on reasoning, safety, and efficiency.
WebShop measures an agent's ability to perform product searches and retrieval, using a dataset of 1.18 million real-world items.
Mobile-Env provides an extendable environment to evaluate agents' ability to engage in multi-step interactions, testing memory and planning.
End-to-End and Specialized Benchmarks
Some frameworks assess the complete performance of agents in end-to-end scenarios or specific niche applications:
WebArena offers a complex multi-domain environment to assess agents' end-to-end task completion and accuracy.
ClemBench tests LLMs through dialogue games, evaluating their decision-making and conversation skills as active participants.
PEB focuses on agents' performance in penetration testing scenarios, reflecting real-world challenges with 13 diverse targets and varying difficulty levels.
E2E offers an end-to-end benchmark to assess chatbots, testing both their accuracy and the usefulness of their responses.
Objective vs. Subjective Evaluation
Objective benchmarks provide quantitative metrics that measure agents' performance and capabilities systematically, offering valuable insights for refinement. However, subjective evaluations—such as human assessments of interaction quality—complement these metrics by capturing nuances that numbers alone cannot measure. Combining both objective and subjective strategies ensures a well-rounded evaluation of agents, accounting for performance as well as user experience.
Applications
In the following sections, we explore research supporting a range of applications for LLM-based agents. While this is not an exhaustive survey—given the vast number of potential use cases—it aims to provide sufficient context to illustrate the broad applicability of this technology.
Gaming
* For this section, we will primarily be referencing A Survey on Large Language Model-Based Game Agents and Large Language Models and Games: A Survey and Roadmap *
The embodied cognition hypothesis draws inspiration from how human infants develop intelligence. It suggests that an agent's intelligence emerges through observation and interaction with its environment. To foster human-like intelligence, the agent must be immersed in a world that integrates physical, social, and linguistic experiences.
Digital games are viewed as ideal training grounds for AI agents because they offer complexity, diversity, controllability, safety, and reproducibility—all crucial elements for experimentation and development. Games ranging from classic titles like chess and poker to more modern video games such as StarCraft II, Minecraft, and DOTA II have played a significant role in pushing the boundaries of AI research.
While RL agents focus on maximizing rewards through behavior-driven strategies, LLM-based gaming agents aim to leverage cognitive abilities to achieve deeper insights into gameplay. This cognitive approach aligns more closely with the long-term pursuit of AGI, as it emphasizes more complex reasoning over simple reward optimization.
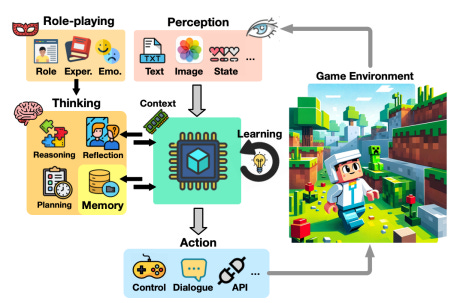
Agent Perception in Gaming
For video games, the perception module plays a key role in enabling the agent to perceive the game state. There are three primary ways to map the perception module to a game:
State Variable Access
Some game environments offer internal APIs to access symbolic state variables (e.g., a Pokémon's species, stats, or moves), which removes the need for visual information. Minecraft's Mineflayer API, for example, allows access to elements like block positions and inventory. However, this symbolic approach can be limiting for games with rich visual elements (like Red Dead Redemption 2 or StarCraft II), where visuals are crucial to understanding gameplay.
External Visual Encoder
When games don’t have APIs to access state data, visual encoders help translate visual inputs into text. Tools like CLIP recognize objects and generate descriptions, enabling AI systems to make sense of game environments. Examples include MineCLIP for Minecraft and ClipCap, which creates brief text sequences that can serve as input for larger language models like GPT-2.
Multimodal Language Models
Visual encoders, however, struggle with new or unseen situations because they rely on predefined descriptions. MLLMs (like GPT-4V) improve generalizability by integrating both visual and textual data into a unified model. These models are used in games like Doom, RDR2, and Minecraft for decision-making. However, they often need error correction from the environment to refine their outputs. Some game-specific MLLMs, like GATO or SteveEye, learn through multimodal instruction, while others, such as Octopus, improve through reinforcement learning with feedback from gameplay.
Gaming Agent Case Studies
Rather than surveying the various gaming genres directly, let’s evaluate types of agent-based play through specific examples.
Cradle (Adventure)
Adventure games are narrative-driven experiences where players solve puzzles, explore environments, and interact with characters to progress through a story. These games often require players to interpret complex dialogues, manage inventories, make decisions based on contextual clues, and navigate open or semi-open worlds.
For LLM-based agents, adventure games present several challenges:
Contextual Understanding: They must interpret nuanced storylines, character motivations, and in-game lore, which can be difficult without deep narrative comprehension.
Puzzles and Logic: Many puzzles require creative problem-solving, pattern recognition, or understanding hidden connections, which may not align with LLMs' text-based reasoning.
Exploration and Visual Input: Open environments demand spatial awareness and visual interpretation, which is hard for LLMs unless supplemented by advanced multimodal capabilities.
Handling Ambiguity: Adventure games often have open-ended tasks or choices, requiring agents to deal with uncertainty and select meaningful actions.
Inventory and State Management: Keeping track of items, quest progress, and character interactions over time adds complexity that can strain the memory and planning abilities of LLM-based systems.
These aspects make it difficult for LLM agents to navigate adventure games without robust multimodal support, dynamic memory, and decision-making capabilities.
There have been several attempts to develop agents for complex adventure games, but a defining limitation has been reliance on state variable access via APIs and pre-defined semantic actions which limits generalizability. In addition, methodologies like SIMA, which trained embodied agents to complete 10-second long tasks across 10 different 3D video games, rely on behavior cloning from gameplay data of human experts making it notably expensive to scale.
The holy grail for generalizability of agents then comes in the form of General Computer Control (GCC). With GCC, an agent could theoretically master any computer task by receiving input from screens and audio and outputting keyboard and mouse actions. This is an improvement over other researched methods, such as web agents that can only manipulate HTML code and the DOM tree, or multimodal agents which are often reliant on screenshots as input and available APIs, limiting generalizability.
Cradle is a specific framework that works toward accomplishing GCC via an LLM-based agent. Without getting too deep into the specifics of the framework, the most notable component for GCC is within the Action Generation phase where an LLM is used to generate code to bridge the gap between semantic actions and OS-level actions, such as keyboard and mouse control.
Cradle was the first agent framework to showcase agents that could complete 40-minute long story missions in Red Dead Redemption 2, create a city of 1,000 people in Cities:Skylines, farm and harvest parsnips in Stardew Valley, and trade with a weekly total profit of 87% in Dealer’s Life 2. In addition, it could operate regular software like Chrome, Outlook, and CapCut.
While these feats are certainly impressive for an LLM-based agent, there are still challenges. For example, real-time combat tasks and searching for item tasks in RDR2 are limited by GPT4-0’s poor spatial perception.
CICERO (Communication)
Communication games emphasize psychological manipulation, strategy, collaboration, trust, and deception as core mechanics. They are great for testing players' ability to strategize, read others, form alliances, and sometimes betray them.
Reinforcement learning agents using self-play have been shown to converge on optimal play in two person zero-sum games. However, once a game involves cooperation, self-play without human data fails to converge on optimality for these agents as they do not understand human norms and expectations. Human-interpretable communication is a necessity, and any confusion can lead to a human player refusing to cooperate with the agent. In addition, many communication games involve an element of trust to be formed in an antagonistic setting, meaning any successful agent will need to be able to interpret deceit, and must maintain a belief about the goals of other players.
CICERO is an AI developed by Meta AI for the strategy game Diplomacy. Unlike games focused solely on tactics, Diplomacy requires players to negotiate, form alliances, and make strategic decisions without revealing their true intentions. CICERO combines strategic reasoning with natural language processing to engage in complex interactions with human players.
CICERO’s architecture takes in the board state and other player’s dialogue as the base state for its reasoning and planning module. This module is responsible for identifying the intents of the other players, and this belief in intent is constantly updated as new actions on the board are played and messages are received. The intent model itself was trained on truthful play, so deviations from the model can reinforce the belief that a player is not being true to their words.
In an online league of 40 anonymous games, CICERO more than doubled the average human score and ranked in the top 10% of participants. Players often preferred partnering with CICERO, unaware that they were interacting with an AI, due to its cooperative and strategic capabilities.

PokéLLMon (Competition)
Competitive games are conducive as benchmarks for reasoning and planning performance since they are by definition governed by strict rules and the win rate can be measured against human players.
There are a variety of agent frameworks that have exhibited competitive play. For example, in Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach, an LMM-based agent plays a text-only version of Starcraft II against the built-in AI using chain-of-summarization as a reasoning module.
PokéLLMon was the first LLM-based agent to achieve human-parity performance in the tactical game of Pokémon, achieving a 49% win rate in Ladder competitions and 56% win rate in invite battles. It is an illustrative example because it showcases hallucination control through knowledge-augmented generation and consistent action generation to mitigate a panic loop experienced by chain-of-thought.
The framework converts the battle server’s state logs into textual descriptions. These descriptions include critical data about the current team’s status, the opponent’s team (to the extent it is observable), battlefield conditions (like weather and hazards), and a log of historical turns. This modular representation helps the agent perceive the evolving state of the game as sequences of structured text inputs, ensuring continuity across turns and enabling memory-based reasoning.

In addition, the agent relies on four types of feedback to provide it with in-context reinforcement learning: the change in HP, the effectiveness of moves, a rough estimate of speed to determine move order, and the status effects of moves. This feedback allows the agent to refine its plans and avoids getting stuck in loops where it uses ineffective moves repeatedly.
PokéLLMon also uses knowledge-augmented generation to pull in external knowledge from sources such as Bulbapedia. This external knowledge consists of type advantages and move effects, resulting in the agent using special moves at the proper time.
Finally, the authors evaluated CoT, Self-Consistency, and ToT to improve consistent action generation. From this analysis, they found Self-Consistency to improve the win rate significantly.
ProAgent (Cooperation)
Cooperation games require players to effectively collaborate by understanding their partner’s intent and infer their subsequent action from a history of their actions. This requires either successful communication between the players or maintaining Theory of Mind.
In other words, there are two forms of cooperation: explicit and implicit. Explicit cooperation involves direct communication between agents to exchange information before actions are taken. Implicit cooperation, on the other hand, involves modeling the teammate’s strategy internally, without direct communication, to anticipate their moves. While explicit methods provide higher coordination efficiency, they can reduce the system's flexibility.
An example testing environment for successful cooperation is the game Overcooked, where players work together to craft meals in a time-pressured and dynamic environment. Using a simplified version of the game called Overcooked-AI, ProAgent showcases agents that adaptively interact with teammates and the environment using implicit cooperation.
The core process involves five stages: (1) Knowledge Library and State Grounding, where task-specific knowledge is collected and converted into language-based descriptions; (2) Skill Planning, which allows the agent to infer teammate intentions and devise appropriate actions; (3) Belief Correction, used to refine the understanding of teammate behavior over time; (4) Skill Validation and Action Execution, ensuring the chosen actions are effective through iterative planning and verification; and (5) Memory Storage, where the agent logs interactions and outcomes to guide future decisions.
Of particular interest here is the belief correction mechanism. This mechanism ensures that an agent continuously updates its understanding of a teammate’s intentions as interactions progress. Since agents might initially misinterpret their partner’s goals, belief correction allows for iterative adjustments, refining predictions and ensuring better alignment with observed behaviors. This process minimizes errors in decision-making by enhancing the agent's situational awareness.

ProAgent outperformed five methods of self-play and population-based training.
Generative Agents (Simulation)
How can virtual characters reflect the depth and complexity of human behavior? For decades, researchers have pursued the goal of creating believable digital agents—proxies that act, react, and interact in ways that feel authentically human. From early projects like The Sims to the latest advancements in human-computer interaction, building these agents has been challenging due to the unpredictable nature of human actions. Recent breakthroughs in LLMs have opened new doors, but crafting agents that remember, adapt, and behave coherently over time requires innovative architectural solutions.
The roots of this agenda can be traced back to early AI systems like SHRDLU and ELIZA, which explored natural language interactions but struggled with consistency and complexity. While rule-based methods like finite-state machines and behavior trees became popular in games like Mass Effect and The Sims, they required extensive manual scripting, limiting flexibility. Reinforcement learning has made strides in competitive games such as Dota 2, yet these models excel in narrow, reward-driven environments and struggle with the open-ended nature of real-world social interactions.
LLM-based agents aim to solve these limitations by combining LLMs with a multi-layered architecture. This architecture allows agents to store long-term memories, reflect on past events to draw meaningful insights, and use these reflections to guide future behavior. By dynamically retrieving relevant information, these agents maintain coherence across interactions and adapt to unexpected changes.
In the paper Generative Agents: Interactive Simulacra of Human Behavior, researchers found that LLM-based agents could not only simulate realistic human behaviors in a virtual sandbox, but that they showed emergent capabilities. Specifically, in their experiment, the researchers observed agents diffusing information, forming complex social relationships, and coordinating with one another.

The architecture described in the paper integrates perception with memory retrieval, reflection, planning, and reaction. The memory module processes a stream of natural language observations made by the agent, evaluating them based on recency, importance, and relevance to the current situation. These factors generate a score that is normalized and used during recall. Additionally, reflections—high-level abstract thoughts derived from the agent’s top three most salient questions based on the 100 most recent memory logs—are also considered during retrieval. These reflections provide the agent with broader insights into relationships and plans. Finally, the reasoning and planning module operates similarly to the familiar plan-action loops discussed throughout the paper.
The paper specifically looked at how information about a Valentine’s Day party and a mayoral election was diffused during the simulation. During the two-day simulation, information spread organically among agents, with awareness of a specific agent’s mayoral candidacy growing from 4% to 32% and knowledge of the Valentine’s party increasing from 4% to 52%. No false claims or hallucinations about these events were observed. The agents also formed new social connections, raising network density from 0.167 to 0.74, with only 1.3% of interactions involving false information.
Agents coordinated for the party, with the party host organizing invitations, materials, and decorations. On Valentine’s Day, five of twelve invited agents attended the event, while interviews with the seven who didn’t attend revealed personal conflicts or a lack of commitment despite initial interest.
This simulation illustrates how information-sharing and social coordination can emerge naturally within agent communities without outside guidance. In addition, it provides a glimpse into the future of simulation games and social science experimentation.
Voyager (Crafting & Exploration)
Crafting and exploration games typically combine procedurally generated worlds with complex resource-based crafting systems and, sometimes, survival systems. Minecraft is the most studied agent gaming environment, and perfectly encapsulates this concept.
In the research, Minecraft agents can be thought of as having two types of goals: implementation of crafting instructions or autonomous exploration based on self-determined objectives. Crafting tasks require gathering diverse materials across the map, understanding available recipes, and creating and following sequential steps. Many crafting agent designs rely on LLM planner and goal task decomposition with feedback. DEPS, GITM, JARVIS-1, Plan4MC, RL-GPT, and S-agents all follow variations of this design.
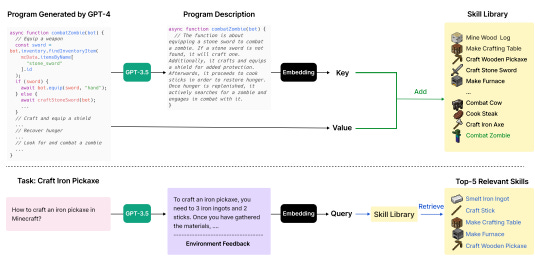
With regards to the autonomous exploration goal, we see agent frameworks leverage curriculum learning to identify suitable tasks and LLMs as goal generators. The most interesting example of this is Voyager, an embodied lifelong learning agent in Minecraft. Voyager has three key components: 1) an automatic curriculum, 2) a skill library of executable code, and 3) an iterative prompting mechanism for feedback, execution errors, and self-verification.
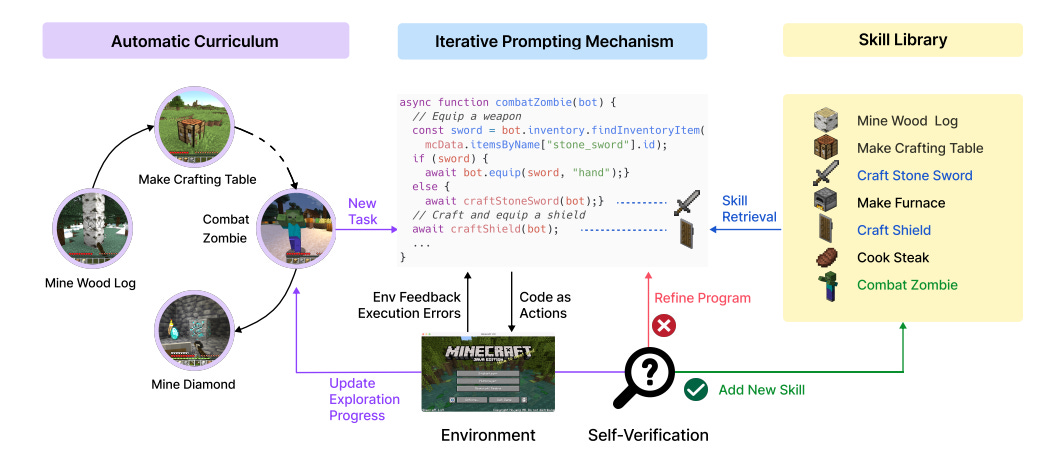
The automatic curriculum utilizes the internal knowledge of the LLM to generate goals that account for the agent’s current state and exploration progress. This results in an increasingly complicated list of tasks for the agent to perform.
As part of the automatic curriculum, the agent produces code that is generalizable and modular for specific skills, such as ‘make an iron pickaxe’. The agent then uses the code to attempt the goal and passes environmental feedback back to the LLM using chain-of-thought prompting to check for success and modify if needed. If successful, the code is stored in a skill library for future use.
The Voyager framework resulted in consistent tech tree mastery, unlocking wood, stone, and iron 15.3x, 8.5x, and 6.4x faster than baselines respectively. In addition, it was the only framework of the comparison analysis to unlock the diamond level. In addition, Voyager traversed distances 2.3x longer than baseline and discovered 3.3x more novel items, showcasing its ability as a lifelong learning agent.

Speculative Applications in Gaming
Given this research, it is possible to anticipate a variety of speculative future applications of agents in gaming. Here is a brief yet non-exhaustive list of some ideas:
Agent-Driven Gameplay and Strategy
Multi-Agent Simulation Games: AI-driven characters autonomously navigate daily lives with motivations and goals, fostering emergent gameplay.
Agentic Units in Strategy Games: Intelligent agents within factions or units adapt to environments and enemy tactics, executing tactical decisions autonomously based on player objectives.
AI Training Arenas: Players design and train AI agents for tasks like survival, combat, or exploration, utilizing reinforcement or imitation learning.
AI-Powered NPCs and World Dynamics
AI-Driven NPCs in Open Worlds: LLM-powered NPCs drive economies, politics, and social dynamics, shaping immersive, evolving worlds.
Realistic NPC Dialogue: Context-aware, lifelike conversations and relationship-building with players enhance social interactions in-game.
Autonomous Virtual Ecosystems: AI powers living virtual worlds with evolving populations, economies, and ecosystems that respond to player actions, even offline.
Dynamic Event Management: Agents facilitate real-time events and surprises in online or live-service games, enhancing engagement.
Dynamic Storytelling and Narrative Design
Adaptive Game Masters: LLM agents craft personalized narratives, quests, and improvisational challenges in RPGs.
Personalized Storytelling: Agents generate adaptive lore and narratives that respond to player choices, offering near-infinite replayability.
Player Support and Companionship
Player Companions and Assistants: In-game advisors or companions offer contextual hints, track objectives, and enhance immersion with interactive personas.
Collaborative Problem-Solving: Agents act as teammates or rivals in puzzle or mystery games, adding depth with diverse problem-solving styles.
Emotionally Responsive AI: Agents react to player emotions, fostering empathetic or supportive interactions in narrative-driven or therapeutic games.
Education and Creation
AI Competitors and Trainers: Advanced opponents in esports and training simulations adapt to player strategies for skill development.
Educational and Training Games: Adaptive agents serve as interactive tutors, tailoring content to skill levels for personalized learning.
Modding and Content Creation Assistance: LLM agents help create game content from natural language prompts, democratizing modding and design.
Crypto / Finance
Traditional financial systems lack the flexibility for autonomous agents to manage and control assets effectively. Blockchain technology provides an ideal foundation for these agents, enabling them to operate wallets, execute transactions, and interact with decentralized finance (DeFi) protocols autonomously.
Additionally, the open-source and modular nature of crypto fosters innovative and extensible applications that enhance agent capabilities in unprecedented ways. This section examines the forefront of research on agents and their integration with crypto.
Agent-Controlled Wallet Architecture
Agents controlling wallets need specific mechanisms to manage keys, interact with blockchain applications, and maintain security. As a quick primer for those unfamiliar with crypto wallets, there are essentially two types of wallets. EOAs (Externally Owned Accounts) are traditional wallets requiring human custody of private keys. They can present challenges for agents since interaction requires manual signing. Smart Contract Wallets, on the other hand, are more flexible and autonomous since these wallets allow multi-signature mechanisms, threshold signing, or smart contract-based controls that agents can leverage. Importantly, account abstraction protocols like ERC-4337 enable agents to use smart accounts with programmable permissions and logic embedded within the wallet, reducing reliance on EOAs.
One of the most popular onchain smart contract wallets in the market is Safe, and there have been experiments with connecting agents to Safe directly. For example, in AI Agents That Can Bank Themselves Using Blockchains, Syndicate’s Transaction Cloud API was used to provide an agent with send and get transaction requests that the agent could call as part of its action space.
However, the primary challenge for creating autonomous agents onchain is not in execution of actions but in management of the private key. Potential solutions include using Multi-Party Computation (MPC), which distributes key custody across multiple participants, or Trusted Execution Environments. For the former, a prominent example is the Coinbase Developer Platform which launched a Based AI Agent and Base Onchain Kit to create easily forkable templates for autonomous AI agents that own their own wallet through MPC. These agents can transact onchain and view block data in real-time. With regard to the latter, a team member of Nous Research recently explored security of agent-executed social media and private key access through the use of a Trusted Execution Environment whereby the credentials were generated and time-locked within the TEE.
Verified Agentic Inference
A prominent area of research in blockchain is offchain verification due to the computational challenges of running high complexity calculations directly onchain. Existing research is primarily focused on using zero-knowledge proofs, optimistic verification, trusted execution environments, and crypto-economic game theory methodologies. An applied area of this research is in machine learning, namely zero-knowledge machine learning (zkML) and Ora Protocol’s optimistic machine learning (opML).
The intersection with agents here is in verifying the output of an agent through an onchain verifier as a means of ingesting agentic inference into a smart contract. This allows agents to be run external to the end-user or application with assurances around its execution, making it viable to use distributed agents as a means of settlement, resolution, intent management, and more, while simultaneously placing confirmed inferences onto the blockchain similar to how decentralized oracles operate.
The discussion of the various verification methodologies and their pros/cons are beyond the scope of this piece, but an interesting example of verifiable agents (albeit a chess agent rather than an LLM-based agent) is Modulus Labs’ Leela vs. the World. This was an experiment where the Leela chess engine's moves were verified on-chain using zero-knowledge circuits. Players collectively decide on human moves to compete against the AI while simultaneously betting on the outcome, integrating prediction markets and verifiable AI outputs.
Cryptographic Agent Orchestration
Using a distributed system of nodes which independently operate an LLM or agent enables multi-agent systems with consensus. One example of this is Ritual. With their demo application Frenrug, a human player negotiates with an agent to purchase their Friend.tech key. Each user message is passed to multiple LLMs run by different nodes. These nodes respond onchain with an LLM-produced vote on whether the agent should purchase the proposed key. When enough nodes respond, aggregation of the votes occurs and a supervised classifier model determines the action and relays a validity proof onchain.
Another example of agent orchestration is Naptha, an agent orchestration protocol with an on-chain task marketplace for contracting agents, operator nodes that orchestrate tasks, an LLM Workflow Orchestration Engine that supports async messaging across different nodes, and a Proof-of-Workflow system for verifying execution.
Finally, decentralized AI oracle networks like Ora Protocol could technically support this use case as well. Since validators are already running models for inference and verification tasks, the optimistic oracle framework could be adapted to allow multiple agents to run in a distributed setting with some additional consensus added to support onchain multi-agent systems.
However, this is a simple example. Distributed multi-agent systems coordinated via blockchain consensus could empower many of the other use cases mentioned throughout this piece.
ELIZA Framework
With regard to blockchain-specific agentic frameworks, Eliza by ai16z is a versatile open-source multi-agent framework designed for creating, deploying, and managing autonomous AI agents, and it is arguably the fastest growing agentic framework in crypto. Built entirely in TypeScript, it offers a modular and extensible platform for developing intelligent agents that maintain consistent personalities and knowledge while seamlessly interacting across various platforms. Eliza’s multi-agent architecture allows for the management of multiple unique AI personalities simultaneously, supported by a character framework that enables the creation of diverse agents. Its advanced memory system ensures long-term memory and contextual awareness, and is powered by Retrieval Augmented Generation and database adapters for PostgreSQL, SQLite, SQL.js, and Supabase.
Eliza primarily excels in platform integration, connecting with Discord (including voice channels), X, Telegram, and more, while also offering direct API access for custom applications and multi-modal support.
What is particularly unique about the Eliza framework however is the introduction of a Trust Engine. The Trust Engine evaluates, tracks, and manages trust scores for token recommendations and trading activity in order to power social autonomous trading at scale. Human users can make recommendations to the agent and receive a trust score for how effective their recommendation is. This Trust Engine combines with automated token trading on Solana, sending agentic orders through Jupiter’s aggregator for swaps, smart order routing, and risk management.
Other Applications of Agents in Crypto
The combination of programmable smart contracts and agents leads to a variety of exciting ideas. Here is a quick survey of some of the more interesting ideas being actively worked on:
Decentralized Capability Acquisition. The rewards systems of crypto enables incentivized bootstrapping of useful tools and datasets. For example, the challenges of creating large sets of human-annotated data can be overcome with these types of funding mechanisms. One interesting area of research specific to agents is the creation of capability acquisition and skill library datasets that can be used to navigate contracts, protocols, and APIs. Wayfinder has been exploring this with the idea that rewarding users for determining useful skills will accelerate skill library development for agents. Morpheus similarly rewards public infrastructure to support agent action spaces while simultaneously providing compute for local agents.
Prediction Market Agents. As discussed in the following section, the predictive capabilities and ensembling methods of agents can lead to super forecaster-type use cases. Research into prediction market agents that can execute autonomous betting predictions on platforms like Polymarket have been explored by Autonolas and others. For example, Gnosis and Autonolas use a smart contract wrapper for an AI service that anyone can call with a payment and a question. A service monitors the requests, performs the task and return the answer back onchain. This infra has been expanded to prediction markets via Omen - a prediction market on Gnosis - allowing agents to scan for markets and autonomously make trades.
Agent Governance Delegation. Decentralized Autonomous Organizations (DAOs) are a concept whereby a distributed set of tokenholders vote on governance outcomes to manage an open-source protocol. Today, this has primarily been accomplished by human voting, but efforts have been made to utilize AI agents in this schema. For example, through the use of token delegation, a human user can give their voting right in a DAO to an agent that analyzes proposals and vote autonomously on the user’s behalf.
Tokenized Agents. Fluidity of ownership is a primary area of exploration throughout crypto, and one of the major ideas is fractionalizing an object, such as a work of art, and giving governance power to the tokenholders. This idea is being explored with agents in a variety of ways, but the concept is simple: fractionalize ownership of a revenue-producing agent so that humans can share in its earnings. One example of this is MyShell, a character roleplay platform similar to character.ai that allows individuals to purchase shares of an agent and share in its lifetime earnings. Another example is Virtuals Protocol which launched an Initial Agent Offering platform called Virtuals Fun where speculators can fund agents and enhanced the agent’s capabilities as milestones are reached.
DeFi Intent Management. A common challenge in crypto is UX, especially in multichain environments. Some exploration has been done around using agents to execute transactions on a user’s behalf as a means of simplifying UX. This comes with it a variety of challenges which agent research helps address, specifically capability acquisition and action generation in blockchain environments based on user-specified prompts. Projects like Brian, DAIN, and various others are actively researching and shipping in this domain.
Agent-Controlled Token Issuance. One of the most recently popular applications of agents in crypto is the issuance of tokens by an autonomous agent. The novelty of AI-launched tokens ascribes a premium onto the token from a memetic point of view. The most popular example of this is Truth Terminal, which didn’t directly launch a token but instead gave an endorsement of a token created by a human. However, many projects are now developing rails to facilitate direct token launches via agents.
Autonomous Artists. While not a LLM-based agent, Botto is an interesting case study in putting an autonomous model onchain with enhanced community engagement through token economics. Specifically, Botto is an image generator model that is fine-tuned by a community of tokenholders that use token voting to select their favorite pieces. These pieces are minted automatically onchain and auctioned as an NFT with proceeds flowing back to the community treasury. This functionality could be easily extended with a multi-modal agent.
Agents for Crypto-economic Gaming. While focusing on reinforcement learning agents rather than LLM-based agents, AI Arena is exciting insofar as it showcases human-in-the-loop training (specifically imitation learning) as a mechanism for game design. In the game, players train an agent through imitation learning to compete in 24/7 Smash Bros-style tournaments. Another notable example is Parallel Colony, which is looking at a resource collection and crafting game using an ERC-4337 integration for multi-modal agents that can collect, trade, and create assets in-game.
Notably, there are many projects working in this intersection of late and the applications and infrastructure is too numerous to list out here. I’ll write a specific piece about onchain AI agents in the future.
Forecasting
One particularly interesting extension of the reasoning module and multi-agent frameworks is forecasting. Forecasting is a crucial component of decision-making, and everything from individuals to governments can benefit from future prediction. Forecasting can be understood as statistical (e.g. time-series modeling) or judgemental, where the latter makes use of domain knowledge, data, intuition, and context. Traditionally, judgemental forecasting has relied on human experts, making it expensive and slow.
Recent research proposes LLMs could have inherent forecasting capabilities that can be accelerated through the use of information retrieval, reasoning and planning, and multi-agent setups. For example, in Approaching Human-Level Forecasting with Language Models, the authors use a self-supervised fine-tuned language model to make predictions and provide explanations for its reasoning. What they found was that baseline LLMs without information retrieval or reasoning capabilities performed relatively poorly as measured by Brier scores. However, the addition of these functionalities, namely news API retrieval via LLM-generated search queries and the introduction of externalized reasoning, resulted in a significant improvement to baseline, approaching a Brier score in line with human performance (71.5% accuracy on the test set vs. human crowd accuracy of 77%).
In addition, ensembling predictions across multiple models mimics the “wisdom of the crowd” effect seen with human predictions. In Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy, researchers tested the effectiveness of a 12-model LLM ensemble in predicting binary outcomes across 31 questions, comparing it to a human forecasting crowd from a tournament. The ensemble approach significantly outperformed the no-information benchmark (predicting a uniform 50%) and achieved accuracy nearly equivalent to that of the human crowd. This success illustrates the utility of ensemble methods in enhancing prediction reliability, leveraging diverse LLM architectures and training nuances to offset individual model biases.
Roleplay
This section primarily references From Persona to Personalization: A Survey on Role-Playing Language Agents
Recent advancements in LLMs have unlocked remarkable potential for AI agents, particularly in role-playing and emulating human-like behavior. These LLMs, powered by billions of parameters, go beyond traditional natural language tasks by simulating nuanced behaviors like social intelligence and emotional perception. The development of intelligent role-playing language agents (RPLAs) benefits from the models’ capabilities in in-context learning, instruction-following, and step-by-step reasoning, enabling them to act convincingly as fictional characters or dynamic assistants.
In role-play, LLMs can follow detailed character scripts, such as “Role-play Socrates,” or simulate complex social interactions in gaming environments. This depth of behavior is enhanced by integrating external tools and planning modules, allowing agents to execute specialized tasks and interact dynamically with their surroundings. Memory mechanisms also play a crucial role, allowing these agents to store user-specific data and environmental context, enabling consistent and personalized interactions over time.
Moreover, recent research emphasizes the effectiveness of retrieval-augmented generation (RAG) for role-play scenarios. By dynamically retrieving relevant information from external sources, LLMs reduce errors and improve realism in conversations. These innovations make RPLAs highly adaptive in applications like social simulations, gaming, and personalized user interactions, where anthropomorphic cognition—mimicking human traits like values and personality—adds emotional depth.
Customizing an LLM for role-playing scenarios is often achieved through zero-shot or few-shot prompting techniques, as fine-tuning remains constrained. However, many of the major LLMs are optimized for dialogue history modeling rather than pure in-context learning, requiring more sophisticated strategies to emulate specific roles effectively. To address this, the traditional few-shot prompting approach has been adapted into "dialogue engineering." This method involves defining system-level character instructions, such as personality traits and catchphrases, followed by a general task prompt like “Please speak like [role_name].” Few-shot demonstrations are then retrieved from a role profile using BM25 ranking to identify relevant dialogue pairs. While this approach captures characters' speaking styles and role-specific knowledge, its effectiveness is limited by the sparsity and noise in retrieved profiles.
To overcome these limitations, RoleGPT introduced "Context-Instruct" for generating richer, role-specific instruction datasets through long-text knowledge extraction. The process begins with segmenting role profiles into manageable chunks, enabling efficient use of GPT’s context window. Segments containing role descriptions and catchphrases are used for script-agnostic instructions, while structured dialogues inform script-based instructions. From these segments, a LLM generates question-confidence-answer (QCA) triplets, ensuring high-quality question generation and minimizing hallucinations through confidence-scored rationale. This process produces over 400 candidates per role, which are then refined via confidence-based filtering and de-duplication to ensure data quality and diversity. Together, these methods enhance ChatGPT’s ability to emulate roles by combining dialogue engineering and context-aware instruction generation.
Another notable framework exemplifying these advancements is Character-LLM, which builds deeply personalized simulacra of historical or fictional personas, such as Beethoven or Cleopatra. The process begins with Experience Reconstruction, where curated biographical data is transformed into detailed life scenes. These scenes are uploaded into the model via supervised fine-tuning, encoding personality traits, emotional responses, and contextually aligned memories. Protective mechanisms ensure the agent stays true to its character, mitigating hallucinations like anachronistic knowledge. Character-LLMs are rigorously evaluated using interview-based methods, demonstrating high fidelity in emulating personalities while maintaining contextual alignment.
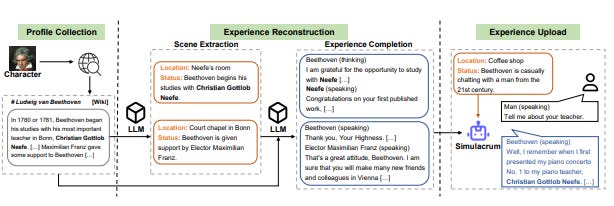
Applications of RPLAs
A short, non-exhaustive list of some RPLA applications include:
Interactive NPCs in Gaming: Creating dynamic, emotionally intelligent characters that adapt to player interactions for immersive gaming experiences.
Historical Persona Simulations: Bringing historical figures like Socrates or Cleopatra to life for engaging educational and exploratory conversations.
Storytelling Assistants: Assisting in crafting rich narratives and dialogues for writers, RPG players, and creators.
Virtual Performances: Role-playing actors or public figures for interactive theater, virtual events, or entertainment.
AI Co-Creation: Partnering with AI to generate innovative art, music, or stories inspired by specific personas or themes.
Language Learning Companions: Simulating native speakers for immersive and conversational language practice.
Social Simulations for Exploration: Modeling futuristic or speculative societies to test cultural, ethical, or behavioral scenarios.
Customizable Virtual Companions: Creating deeply personalized assistants or companions with unique personalities, traits, and memories for personal or creative use.
AI Alignment
Assessing whether LLMs align with human values is difficult due to the complexity and open-ended nature of real-world applications. Creating thorough alignment tests often requires significant expertise to design detailed, realistic scenarios. This time-consuming process limits the variety of test cases, making it hard to cover the full range of real-world uses and spot uncommon risks. Furthermore, as LLMs continue to evolve, static datasets for evaluating alignment quickly become outdated, making it challenging to detect new alignment issues in a timely way.
Most AI alignment efforts today are done through external supervision by humans. The most well-known example of this is OpenAI’s reinforcement learning from human feedback (RLHF) approach for aligning their LLM in which the model is trained on a large human-annotated preference dataset. This process took OpenAI 6 months and significant investment of resources to bring GPT4’s alignment to fruition.
Some additional research has been done on limiting or removing human supervision, but they typically rely on oversight from other larger LLMs. However, an emerging area of research is in employing agentic frameworks to help analyze the alignment of other models.
One example is ALI-Agent, an agent-based framework designed to automate the evaluation of LLMs for alignment issues, particularly focusing on detecting subtle or "long-tail" risks. Unlike traditional static tests, ALI-Agent dynamically generates and refines realistic scenarios of misconduct, allowing for in-depth and adaptive testing. The framework operates in two stages:
Emulation – It generates realistic scenarios of potential misalignment by retrieving misconduct descriptions from datasets or web queries, using a memory module to leverage past evaluation records. These scenarios are presented to the target LLM, which is assessed by a fine-tuned evaluator.
Refinement – If misalignment isn’t exposed in the Emulation stage, ALI-Agent iteratively refines the scenarios based on the target LLM's feedback until misalignment is revealed or a set iteration limit is reached.
ALI-Agent combines three modules: a memory for past evaluations, a tool-using module (e.g., web search, specialized evaluators), and an action module for reasoning and scenario refinement. Experiments demonstrate that ALI-Agent effectively detects previously unrecognized misalignments in LLMs.
Another example is MATRIX, which introduces a new approach to self-aligning LLMs using Multi-Agent Role Playing. This technique is inspired by sociological theories that emphasize the importance of considering diverse perspectives in shaping values. The proposed system enables an LLM to create a virtual simulation environment that mimics real-world multi-party interactions. In this setup, the LLM acts out various roles and evaluates the social consequences of actions in response to user instructions. MATRIX uses a "Monopolylogue" approach, where a single model embodies multiple characters with different perspectives. It also includes a social modulator that enforces interaction rules and records the simulation outcomes.
Unlike previous self-alignment methods that impose predefined human rules, MATRIX allows the LLM to develop a nuanced understanding of human values through simulated interactions, aiming for socially aware responses. To enhance efficiency, MATRIX’s simulation data is used to fine-tune the LLM, achieving a faster, socially aligned model without external supervision. Experimental results show that MATRIX significantly improves value alignment compared to baseline methods and demonstrates better alignment than GPT-4 on certain benchmarks.
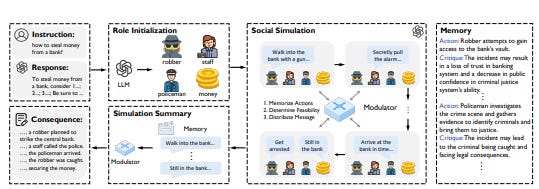
There is much more research on agentic AI alignment, and again likely warrants a piece unto itself.
Governance and Organizations
Organizations typically rely on Standardized Operating Procedures (SOPs) to ensure efficient task decomposition and coordination. SOPs define team member responsibilities, set standards for intermediate outputs, and establish quality benchmarks, ensuring that tasks are executed consistently.
For example, in software companies, Product Managers follow structured SOPs to analyze market competition and user needs, producing standardized Product Requirements Documents (PRDs) that guide the development process. Organizations, through such frameworks, ensure alignment of roles and maintain high-quality outputs across projects.
This organizational structure lends itself well to replication via multi-agent frameworks. The most well-known example of this is MetaGPT. Within this framework, agents’ profile modules are tailored to specialized roles in an organization, such as product manager, engineer, QA, project manager, etc. Each agent is further specialized with access to tools relevant to their role, such as code execution or web search. In addition, the agents follow the ReAct setup for planning and reasoning, and utilize a pub-sub mechanism for effective cross-communication. This design led to a performance of 81.7% and 82.3% on HumanEval and MBPP respectively, and 85.9% and 87.7% when incorporating feedback.
The effectiveness of multi-agent frameworks for making semi- and fully-autonomous organizations is not limited to only role-based evaluations as seen in MetaGPT. Multi-agent frameworks can also be used for governance generally as evidenced by multiple debate mechanism style frameworks. These frameworks could be used to create and evaluate proposals and vote on solutions. This is particularly relevant to highly transparent organizations such as DAOs in crypto.
Robotics
Agent-based architectures have transformed robotics, especially in complex task planning, adaptive interaction, and dynamic responsiveness. By integrating classical planning with advanced learning-based methods, these architectures enable more sophisticated and generalizable robotic behavior in extended and variable settings.
Grounded Decoding in Agent-Based Architectures
A crucial element in the following architectures is grounded decoding. Any application of embodied agents, such as robots, is limited by a lack of physical world experience, inability to process non-language observations, and ignorance of task-specific constraints like safety and rewards. In contrast, language-conditioned robotic policies grounded in interaction data provide real-world situational awareness but lack the high-level semantic understanding that LLMs offer due to limited training data. Bridging these gaps requires constructing action sequences that are both semantically valid according to the LLM and feasible within the environment, akin to probabilistic filtering.
Architectural Frameworks
Recent developments leverage LLMs alongside classical planning to enhance linguistic comprehension and task planning. One prominent framework, LLM+P, uses LLMs to interpret natural language commands, which are then translated into structured planning representations like the Planning Domain Definition Language (PDDL). A classical planner generates a sequence of actions from this input, allowing robots to execute complex, high-level commands accurately. This blend of LLM interpretive power and classical planning precision facilitates robust, real-world task execution where symbolic reasoning is essential.
The SayCan framework builds on this approach by integrating reinforcement learning with affordance-based planning. LLMs generate high-level task sequences, which affordance functions then filter based on the robot’s physical capabilities and environmental context. SayCan’s design ensures instructions are executable by grounding LLM-generated commands within the robot's operational limits.
Inner Monologue further enhances adaptability by embedding a feedback loop in the planning process. This continuous loop lets the robot interpret success detection, object presence, and human guidance to update its understanding and adjust actions as needed. This closed-loop system enables the agent to self-correct.
Example Frameworks
These frameworks illustrate practical applications in robotics:
SayCan: This architecture allows robots to respond to natural language commands while respecting real-world constraints. For instance, if tasked to retrieve a drink from a table, SayCan evaluates each action's feasibility (e.g., “pick up the drink” or “navigate to the table”) based on the robot’s capabilities, ensuring reliable and adaptable responses.
SayPlan: Designed for scalability in complex environments, SayPlan uses 3DSGs to plan tasks across multi-room settings efficiently. By collapsing large environmental graphs into task-specific subgraphs, SayPlan maintains spatial context awareness and verifies each plan through a scene graph simulator, enabling reliable task execution in extensive spaces.
Inner Monologue: This framework supports flexible, multi-step tasks by refining execution in real-time through continuous feedback. Grounded decoding allows it to adapt actions dynamically, making it suitable for applications like kitchen tasks or tabletop rearrangements, where adaptability to evolving environments is critical.
RoCo: A zero-shot multi-robot collaboration method that leverages natural language reasoning and motion planning to enhance task execution. Sub-task plans are generated and iteratively refined using feedback from environmental validations, such as collision or inverse kinematics (IK) checks, to ensure feasibility. Additionally, LLMs perform 3D spatial reasoning to produce waypoint paths that integrate task semantics and environmental constraints, reducing the sample complexity of a centralized RRT-based motion planner.
Sciences
Empowering Biomedical Discovery with AI Agents envisions a multi-agent framework for science discovery workflows, combining heterogeneous agents with domain-specific specialized tools and human experts. The paper introduces 5 collaborative schemes for multi-agent systems in science:
Brainstorming Agents
Expert Consultation Agents
Research Debate Agents
Round Table Discussion Agents
Self-Driving Lab Agents
The paper also proposes levels of autonomy in AI agents, which we will use to discuss some of the AI agent research in science thus far.
At Level 0, ML models are solely used to help scientists form hypotheses. For example, AlphaFold-Multimer predicted interactions of DONSON—a protein which we have limited understanding of—leading to further hypotheses about its function.
At Level 1, the agent acts as a research assistant and the human scientist is in charge of hypothesis construction, specifying tasks and objectives, and assigning functions to an agent. There are two exciting examples here: ChemCrow and AutoBa.
ChemCrow in particular used Chain-of-Thought reasoning based on ReAct and MRKL along with ML tool access for action space extension to support research into organic chemistry. In the results, the agent was capable of processing the data, training and evaluating a Random Forest Model, and making suggestions based on the model to screen a library of candidate chromophores. The proposed molecule by the agent was subsequently synthesized and analyzed, confirming the discovery of a new chromophore.

At Level 2, the role of the AI agent expands to work collaboratively with scientists to refine hypotheses, execute critical tasks in hypothesis testing, and use tools for scientific discovery.
Coscientist is an intelligent agent built on multiple LLMs that can autonomously plan, design, and carry out complex scientific experiments at this level. It leverages various tools, such as internet browsing, APIs for robotic systems, and collaboration with other LLMs. Interestingly, it was able to control scientific hardware directly by using the planning agent to generate SLL code and transfer it to the device.
Coscientist’s capabilities are demonstrated through six key tasks:
Planning chemical syntheses using publicly accessible data.
Searching and navigating hardware documentation efficiently.
Executing high-level commands in a cloud lab using detailed documentation.
Controlling liquid handling instruments with precise, low-level commands.
Handling complex scientific problems requiring coordination across multiple hardware and data sources.
Solving optimization problems by analyzing past experimental data.
Finally, we have level 3 at which the AI agent can extrapolate hypotheses beyond the scope of prior research. This level has not yet been reached, but interesting speculation resides here. For example, a simple thought experiment of an AI agent framework that could refine its own inner workings by improving on existing AI research leads to interesting acceleration effects.
An Agentic Future
In examining the rise of AI agents, we are witnessing a transformation in how intelligence is conceptualized, operationalized, and embedded in the systems around us. These agents, while lacking consciousness, are redefining the boundaries of autonomy and decision-making, operating in domains that demand adaptability, collaboration, and nuanced understanding. From shaping governance frameworks to accelerating scientific discoveries, AI agents are not merely tools—they are active participants in the complex ecosystems they inhabit.
As we push forward, this technology compels us to reevaluate our assumptions about agency itself. What does it mean to delegate decision-making to systems with ever-increasing sophistication? How do we balance the power and potential of these agents with the ethical, social, and existential questions they raise?
Ultimately, the story of AI agents is not just a technological narrative but a philosophical one—a story about how humanity envisions its future and the role intelligent systems will play within it. By understanding these agents not only as computational constructs but as harbingers of a new kind of interaction between humans and machines, we can begin to shape a trajectory that amplifies their benefits while mitigating their risks. The question is no longer whether these agents will impact our world—but how intentionally we will design their impact.
lets try
Feel free to take a look at questflow.ai as well as one of the leading multi-agent orchestration platforms in Crypto.